How do you find duplicates in SQL?
How do you find duplicates in SQL?
To find duplicates rows in a table you need to use a Select statement that contains group by with having keyword. Another option is to use the ranking function Row_Number().
How do I find duplicate values?
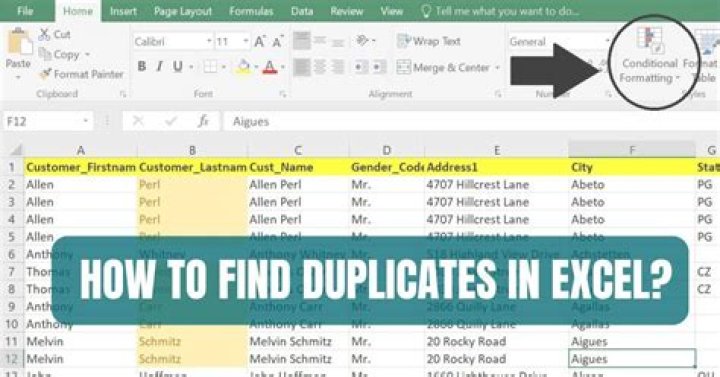
Find and remove duplicates
- Select the cells you want to check for duplicates.
- Click Home > Conditional Formatting > Highlight Cells Rules > Duplicate Values.
- In the box next to values with, pick the formatting you want to apply to the duplicate values, and then click OK.
How do I filter duplicates in SQL?
The go to solution for removing duplicate rows from your result sets is to include the distinct keyword in your select statement. It tells the query engine to remove duplicates to produce a result set in which every row is unique.
How do you find duplicates in database?
To find duplicate records using the Query Wizard, follow these steps.
- On the Create tab, in the Queries group, click Query Wizard.
- In the New Query dialog, click Find Duplicates Query Wizard > OK.
- In the list of tables, select the table you want to use and click Next.
How do I find duplicate records in Oracle SQL?
How to Find Duplicate Records in Oracle
- SELECT * FROM fruits;
- SELECT fruit_name, color, COUNT(*) FROM fruits GROUP BY fruit_name, color;
- SELECT fruit_name, color, COUNT(*) FROM fruits GROUP BY fruit_name, color HAVING COUNT(*) > 1;
How do you add duplicates in SQL?
To select duplicate values, you need to create groups of rows with the same values and then select the groups with counts greater than one. You can achieve that by using GROUP BY and a HAVING clause.
How do I find duplicates in Oracle query?
How do you find common data in two tables in SQL?
7 Answers. If you are using SQL Server 2005, then you can use Intersect Key word, which gives you common records. If you want in the output both column1 and column2 from table1 which has common columns1 in both tables. Yes, INNER JOIN will work.
How do I find duplicate values in two columns in mysql?
Find Duplicate Row values in Multiple Columns SELECT col1, col2,…, COUNT(*) FROM table_name GROUP BY col1, col2, HAVING (COUNT(col1) > 1) AND (COUNT(col2) > 1) AND In the above query, we do a GROUP BY of all the columns (col1, col2) for whom we want to find duplicates.
How do I find duplicate rows in SQL using Rowid?
Use the rowid pseudocolumn. DELETE FROM your_table WHERE rowid not in (SELECT MIN(rowid) FROM your_table GROUP BY column1, column2, column3); Where column1 , column2 , and column3 make up the identifying key for each record. You might list all your columns.
What is duplicate key in SQL?
The Insert on Duplicate Key Update statement is the extension of the INSERT statement in MySQL. When we specify the ON DUPLICATE KEY UPDATE clause in a SQL statement and a row would cause duplicate error value in a UNIQUE or PRIMARY KEY index column, then updation of the existing row occurs.