What is a semi Markov decision process?
What is a semi Markov decision process?
Semi-Markov decision processes (SMDPs), generalize MDPs by allowing the state transitions to occur in continuous irregular times. In this framework, after the agent takes action a in state s, the environment will remain in state s for time d and then transits to the next state and the agent receives the reward r.
How does Markov decision process work?
Markov decision processes are an extension of Markov chains; the difference is the addition of actions (allowing choice) and rewards (giving motivation). Conversely, if only one action exists for each state (e.g. “wait”) and all rewards are the same (e.g. “zero”), a Markov decision process reduces to a Markov chain.
What are the five essential parameters that define an MDP?
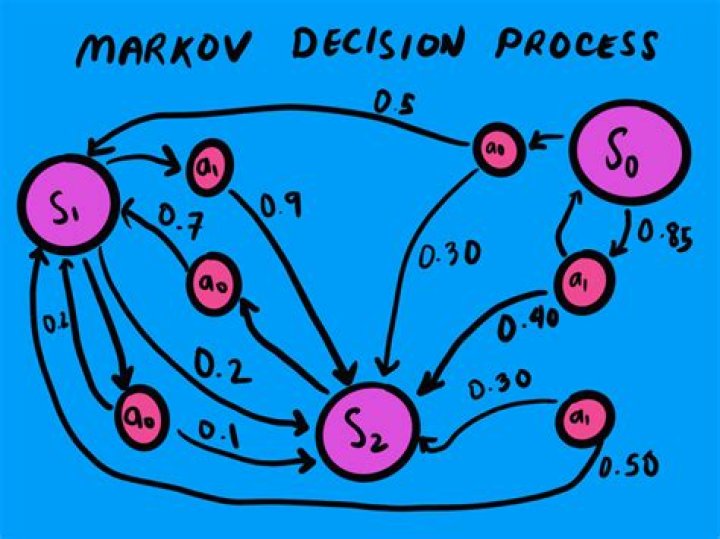
An MDP is defined by (S, A, P, R, γ), where A is the set of actions. It is essentially MRP with actions. Introduction to actions elicits a notion of control over the Markov Process, i.e., previously, the state transition probability and the state rewards were more or less stochastic (random).
What are the elements of MDP?
The components of a MDP include: – the state space, s ∈ S ; – the set of actions, a ∈ A ; – the reinforcement (reward) function, r : S × A × S → ℜ .
What is the difference between a Markov process and a Markov decision process?
Markov Process : A stochastic process has Markov property if conditional probability distribution of future states of process depends only upon present state and not on the sequence of events that preceded. Markov Decision Process: A Markov decision process (MDP) is a discrete time stochastic control process.
What is Markov decision process in reinforcement learning?
Markov Decision Process (MDP) is a mathematical framework to describe an environment in reinforcement learning. The following figure shows agent-environment interaction in MDP: More specifically, the agent and the environment interact at each discrete time step, t = 0, 1, 2, 3…
What is a policy in MDP?
In a finite Markov Decision Process (MDP), the optimal policy is defined as a policy that maximizes the value of all states at the same time¹. In other words, if an optimal policy exists, then the policy that maximizes the value of state s is the same as the policy that maximizes the value of state s’.
Where is MDP used?
MDPs are used to do Reinforcement Learning, to find patterns you need Unsupervised Learning. And no, you cannot handle an infinite amount of data. Actually, the complexity of finding a policy grows exponentially with the number of states |S|.
What is a policy in an MDP?
What are the main components of a Markov decision process Javatpoint?
Markov Process: Markov process is also known as Markov chain, which is a tuple (S, P) on state S and transition function P. These two components (S and P) can define the dynamics of the system.
What is role of Markov decision process in reinforcement learning?
MDP is a framework that can solve most Reinforcement Learning problems with discrete actions. With the Markov Decision Process, an agent can arrive at an optimal policy (which we’ll discuss next week) for maximum rewards over time.
What are the main components of a Markov Decision Process Javatpoint?